
[논문리뷰] DIDN - Deep Iterative Down-Up CNN for Image Denoising
[논문리뷰] DIDN - Deep Iterative Down-Up CNN for Image Denoising
DIDN의 구조
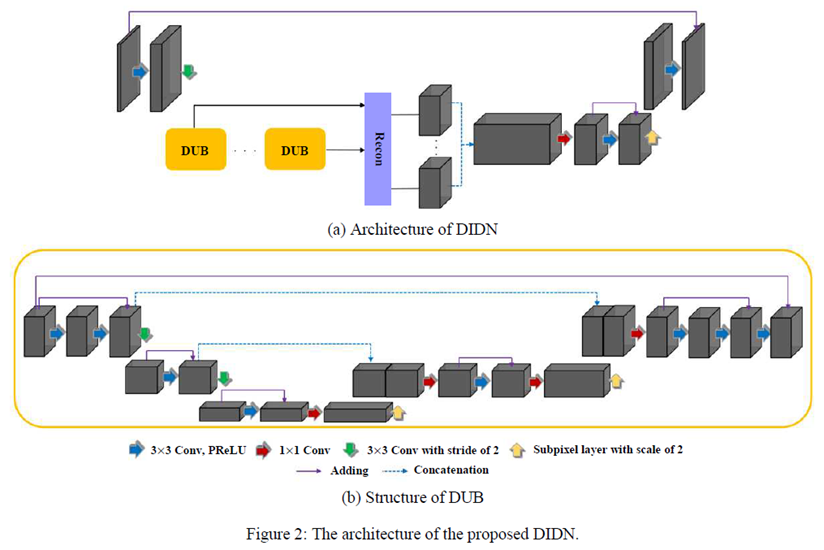
DIDN (Deep Iterative Down-up Network)
DUB (Down Up Block)
Initial Feature Extraction
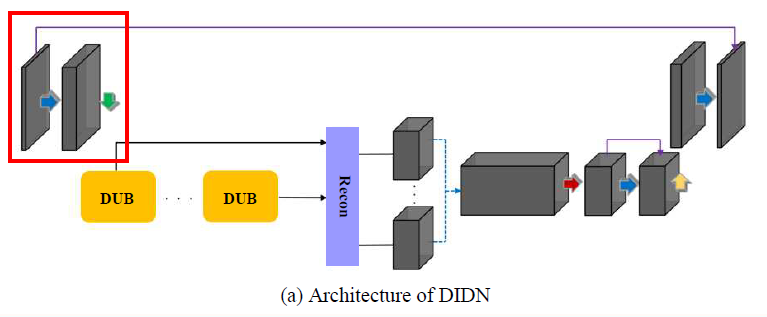
- 3x3 convolution을 통해 N개의 feature 생성 (N=256)
- stride=2 인 3x3 convolution을 통해 feature의 크기를 줄임 (downsampling)
이후의 모든 downsampling 은 학습이 가능한 stride=2인 conv 로 사용
Pooling, sub-sampling 존재
Down-Up Block
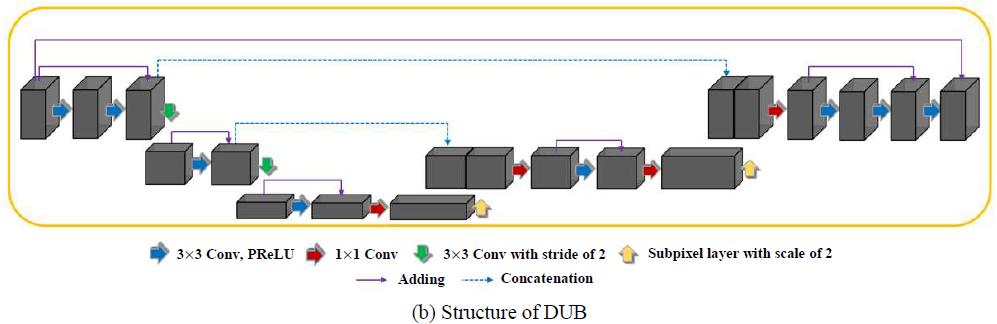
- 구조는 U-net과 유사
- Down sampling은 stride=2인 3x3 convolution을 통해, Up sampling은 subpixel layer를 통해 실행.
- Pixel shuffle 전 1x1 convolution을 통해 feature map 수 증가
U-net에서는 max pooling을 사용했지만, DUB에서는 convolution 사용
subpixel이 계산복잡도 낮춤
Down sampling시 채널수 2배, 크기 4배 감소
Up sampling 전에 채널수 2배 증가해야함으로 1x1 conv 사용
Reconstruction
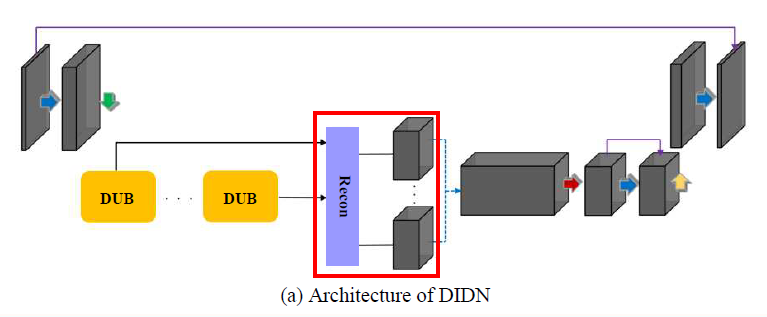
- 모든 local output의 정보를 얻기 위해 DUB의 모든 출력을 입력으로 사용
- 9개의 3x3 convolution, PReLU로 구성됨
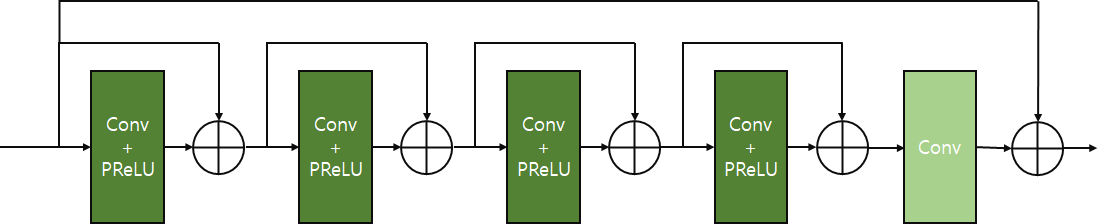
Reconstruction의 구조는 아래와 같다.
Enhancement
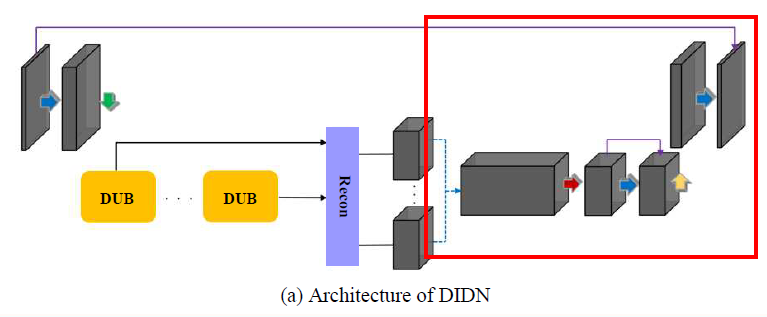
-
Reconstruction의 결과를 concat후 1x1 convolution으로 채널 수 낮춤
-
DUB와 동일하게 subpixel layer로 up-scaling 수행
-
Subpixel layer가 LR서 HR로 디테일한 정보를 전달하기에 denoising에 효율적
Ensemble strategy
- Snapshot ensemble
- Learning rate를 주기적으로 변경하고, 주기마다 weight의 평균을 냄
-
Self-ensemble
-
하나의 input에 대해 rotate, flip을 통해 8개의 output 생성
-
8개의 output의 평균을 최종 결과로 사용
-
-
Model ensemble
-
같은 동작을 여러 모델로 수행한 후 output들의 평균 사용
-
DIDN에 적용시 parameter는 증가하지만, 성능변화가 적어 비효율적
-
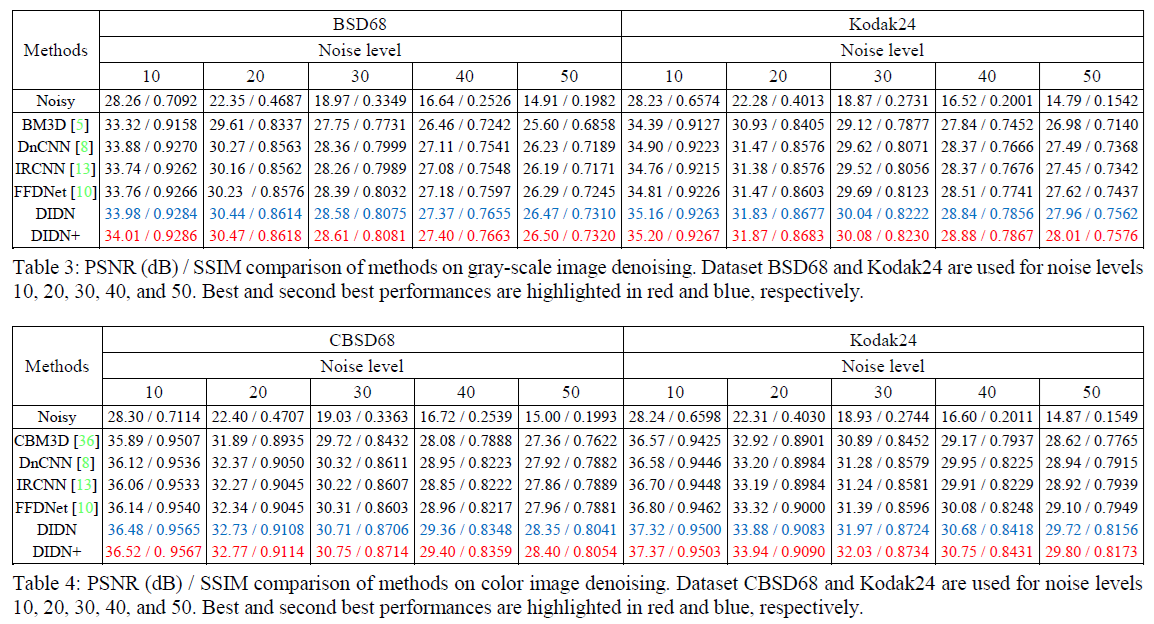
실험 결과
Leave a comment