
[논문리뷰] DenseNet - Densely Connected Convolutional Network
[논문리뷰] DenseNet - Densely Connected Convolutional Network
DenseNet
-
ResNet 이후 논문서 CNN은 input과 layer가 가까울수록 더 정확하다는 것을 보여줌
-
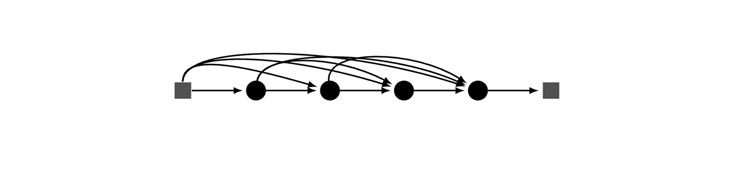
$x_0 … x_{l-1}$ 을 sum이 아니라 concatenation(연쇄)함. 이로 인해 input의 정보가 비교적 온전히 남아있음
-
기존의 Convolution Network : $x_l = H_l(x_{l-1})$
-
ResNet : $x_l = H_l(x_{l-1})+x_{l-1}$
-
DenseNet : $x_l = H_l([x_0,x_1,…,x_{l-1}])$
$H_l$ 은 Batch Normalization, ReLU, convolution의 합성함수를 의미한다.
ResNet는 layer 전후로 추가적 connection이 있지만, 이를 단순히 합하여 더하므로 이전 정보와 다음 정보를 분리하여 해석할 수 없다.
DenseNet의 장점
-
모든 layer가 연결되어 있으므로 Vanishing Gradient 현상을 개선함
-
Feature Propagation(확산) 강화
-
Feature Reuse
-
중복되는 feature map은 다시 학습할 필요가 없기 때문에 Parameter를 절약함
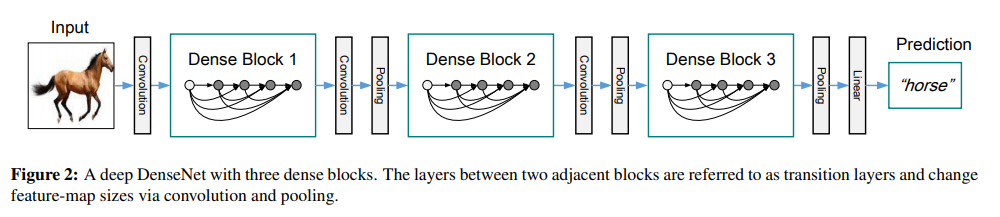
Dense Block이라고 부르는 하나의 connection 덩어리를 만들어서 전통적인 CNN처럼 Convolution , Pooling layer과 함께 순차적으로 Dense Block들을 거쳐서 마지막에 Linear layer후 결과를 뽑아내게 된다.
Growth rate
-
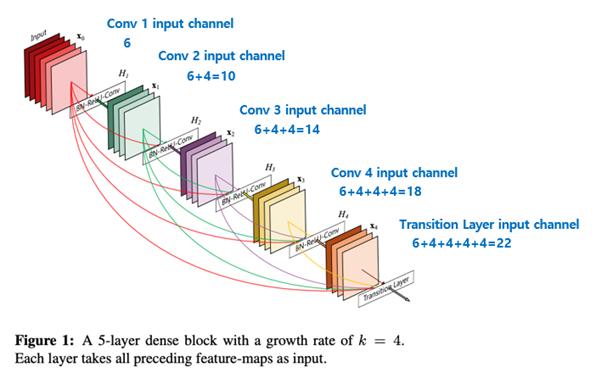
이전의 feature map들이 계속 연결되는 구조이므로, layer당 채널의 개수에 따라 뒤로 갈수록 채널이 증가함
-
Feature map의 채널 개수를 Growth rate(k)라 함
위의 사진은 k = 4 인 경우.
6 channel feature map 입력이 dense block의 4번의 convolution block을 통해 (6 + 4 + 4 + 4 + 4 = 22) 개의 channel을 갖는 feature map output으로 계산이 되는 과정
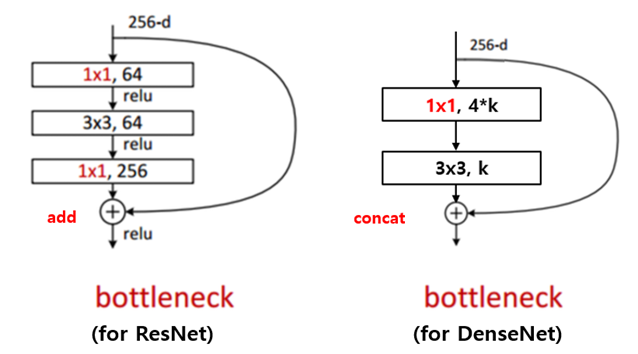
DenseNet BottleNeck layer
-
ResNet과 유사한 bottleneck 구조를 사용함
-
입력 feature-map의 개수를 줄이고 계산 효율을 향상시킬 수 있음
-
비슷한 parameter의 개수로 더 좋은 성능을 보임
Compression
-
Model의 size를 줄이기 위해 transition layer에서 feature map의 개수를 줄일 수 있음
-
0<θ<1 의 값을 가지는 θ를 compression factor라 하고, Denseblock이 m개의 feature map을 가질 때, transition layer에서는 출력 feature map을 ⌊θm⌋개 생성함
-
이후의 실험에서는 θ=0.5로 설정
-
BottleNeck layer를 사용한 모델을 DenseNet-B, Compression layer를 사용한 모델을 DenseNet-C, 둘 모두를 사용한 모델을 DenseNet-BC라 칭함
transition layer = convolution + pooling
Feature Reuse
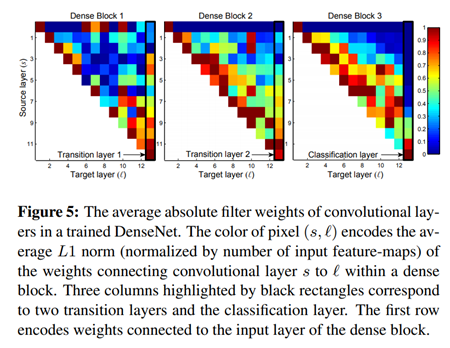
-
모든 layer는 동일한 block 내의 많은 input에 weight를 분산시킴
-
2, 3번째 dense block 내의 layer는 transition layer의 출력에 최소한의 weight만 일관되게 할당
-
맨 오른쪽에 표시된 final classification layer도 전체 dense block의 weight를 사용하긴 하지만, 최종 feature-map에 집중함
위 그림은 Denseblock 내부에서 콘볼루션 레이어들의 필터 가중치의 평균이 어떻게 분포되어있는지 보여준다.
Pixel (s,ℓ)의 color는 dense block 내의 conv layer s와 ℓ을 연결하는 weight의 average L1 norm으로 인코딩 한 것이다.
Transition layer가 중복된 feature(평균 weight가 낮은)를 많이 출력한다는 것을 나타내며, 이는 이러한 출력이 compression되는 DenseNet-BC의 결과와 정확하게 일치한다.
이는 네트워크에서 늦게 생성되는 high-level feature들이 더 있을 수 있음을 나타낸다.
실험 결과
1) DenseNet at ImageNet
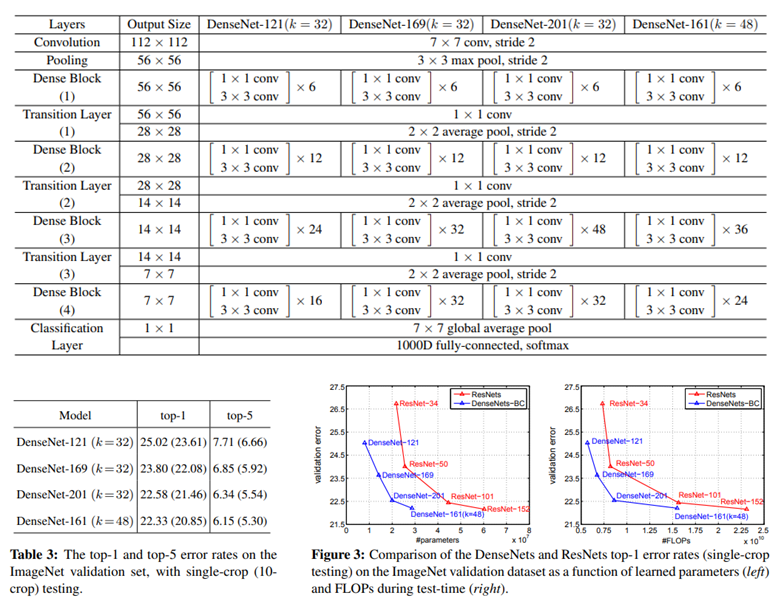
-
Conv layer는 BN-ReLU-Conv 의 순서
-
Layer의 수 에 따라 DenseNet의 종류를 나눔
-
(+) : data augmentation scheme (mirroring/shifting) 적용
-
마지막 구조에서 FC(Fully Connect) 대신 파라미터가 증가하지 않는 global average pooling 사용
2) DenseNet at CIFAR and SVHN
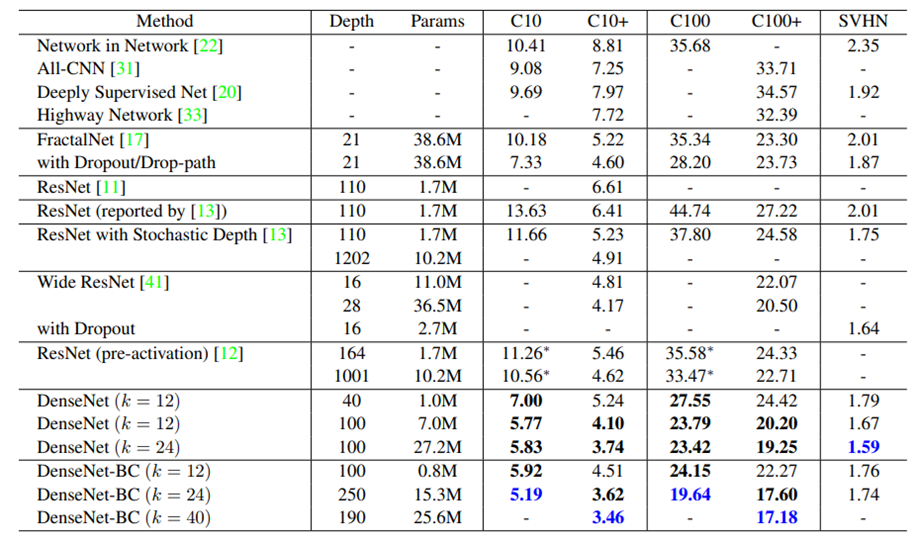
-
k가 증가하면 파라미터의 수가 많아지고 BC(Bottleneck Compression)을 사용하면 파라미터의 수가 줄어듬
-
SVHN(Street View House Numbers)의 경우 BC를 사용하지 않은 네트워크에서 더 좋은 결과가 나온다. 논문에서는 이를 SVHN이 상대적으로 쉬운 작업이기 때문이고 더 딥한 모델이 학습 데이터에 오버피팅 되기 때문이라고 함
3) DenseNet at CIFAR and SVHN
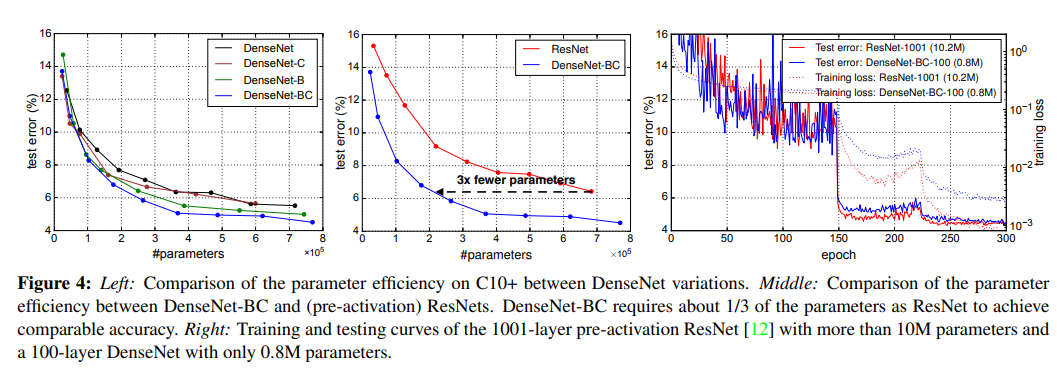
왼쪽 : C10+에서 param의 수
가운데 : DenseNet와 ResNet의 param수 비교 (같은 error에서 3배차이)
오른쪽 : ResNet과 비교. Error는 비슷하지만 param수가 매우 차이남
Leave a comment