
[논문리뷰] SPPNet - Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[논문리뷰] Pyramid_pooling - Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
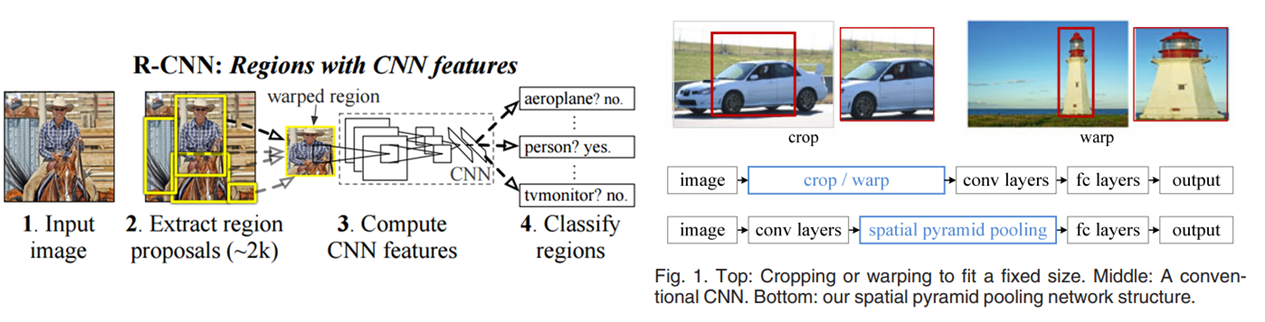
Compare with conventional CNN (R-CNN)
-
FC layer에서 고정된 크기의 입력을 받으므로 기존의 CNN은 입력이미지의 크기가 고정되어야 함 (crop, warp 사용)
-
입력 크기에 관계없이 conv를 진행 후 고정된 크기의 feature map을 출력하는 pooling을 적용함
-
Image Classification나 Object Detection과 같은 여러 task들에 일반적으로 적용할 수 있음
크기조절 없이 컨볼루션시 원본 이미지의 특징을 모두 가진 feature을 얻을 수 있음
또한 이미지크기 변화에 더 견고한 모델을 얻을 수 있음
Convolutional Layers and Feature Maps

conv5 층의 어떤 필터들에 의해 생성된 것임.
그림2-(c) 는 ImageNet dataset에서 이런 필터들에 의해 가장 강하게 activate된 이미지를 보여줌
-
Crop/warp를 하지 않았으므로 feature map의 크기가 다름
-
화살표는 feature의 강한 응답을 가리킴
-
필터는 의미가 있는 내용들에 대해 activate됨
BoW (Bag of Words)
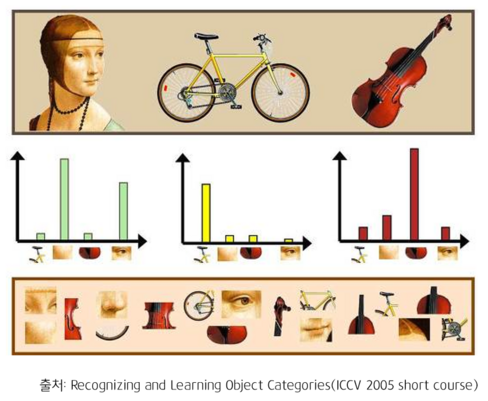
- 다양한 크기의 입력으로부터 일정한 크기의 feature를 추출해 낼 수 있는 방법
- 특정 객체를 분류하는데 굵고 강한 특징에 의존하지 않고 여러 개의 작은 특징을 사용하여 객체를 구별
- SPPNet도 BoW 처럼 이미지를 구성하는 특징들로 이미지를 나타내는 개념
위치는 고려하지 않고 부분으로 물체 구별
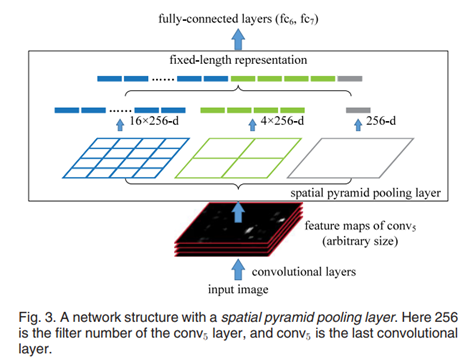
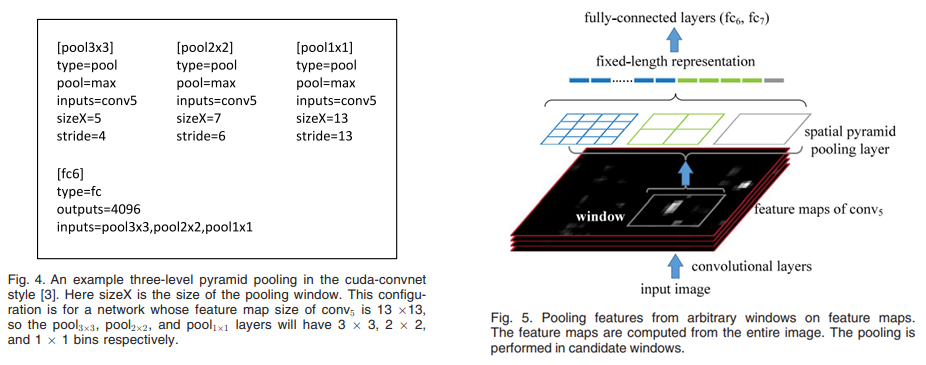
Spatial Pyramid Pooling
-
Convolution 을 거친 feature map들을 input으로 받음
-
피라미드 라고 부르는 각각의 영역으로 나누어줌 (위 그림에선 4x4, 2x2, 1x1)
-
각각의 영역에서 max pooling을 수행 후 이를 이어붙힘
-
최종 output은 kM차원의 벡터 / k = 256, M = (16 + 4 + 1) = 21
SPP-Net for image classfication
-
Single-size training =224x224 size {3x3, 2x2, 1x1} SPP 사용
-
Multi-size training = 180x180, 224x224 size 학습
-
SPPnet을 거친 feature에 softmax를 수행하여 분류에 사용
두 네트워크에서 출력은 동일함
실험 결과
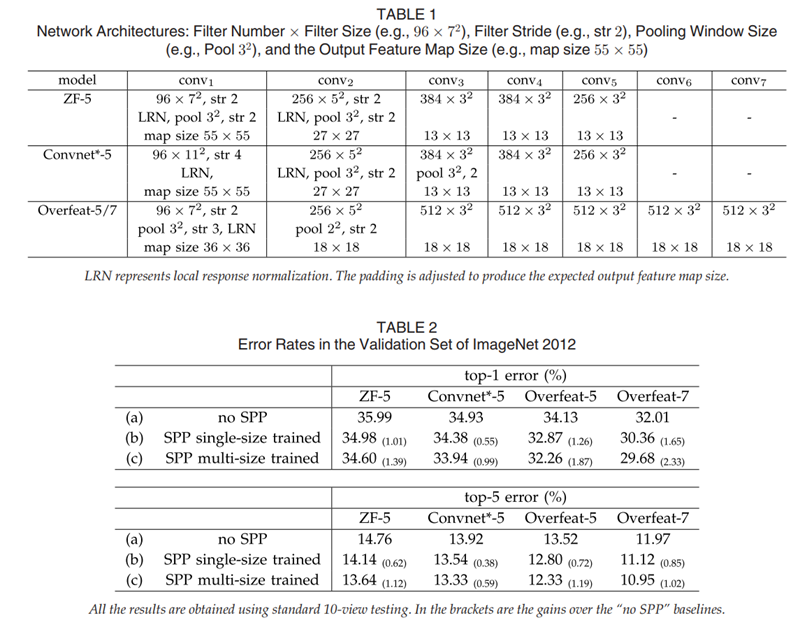
{6x6,3x3,2x2,1x1} (50bins) 와 {4x4,3x3,2x2,1x1} (30bins) 의 차이 거의 없지만, SPP를 사용하고 안하고 차이 큼
SPP-Net for Object detection
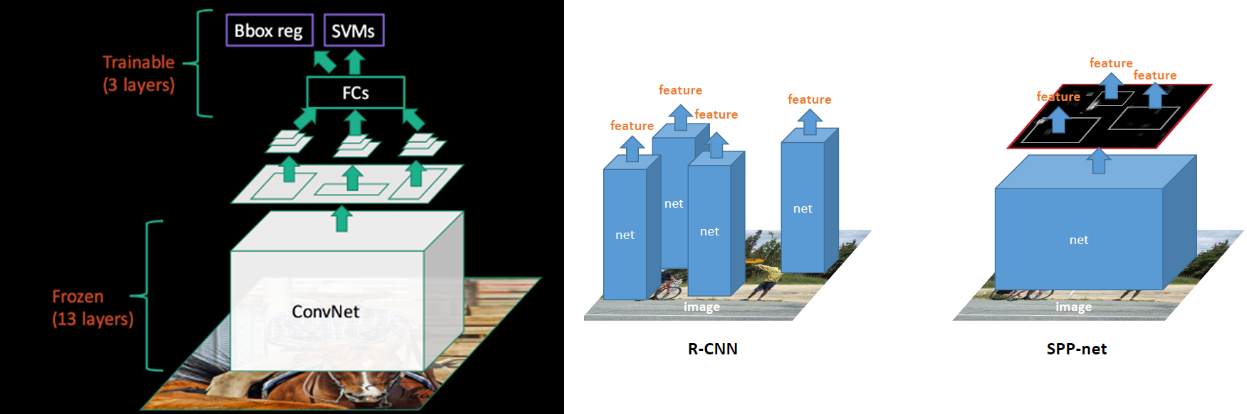
-
R-CNN은 Selective Search로 찾은 2000개의 영역을 모두 고정 크기로 조절한 후, CNN 모델을 통과시켜 feature를 추출함
-
SPPNet은 입력 이미지를 그대로 CNN에 통과시켜 feature map을 추출한 후 feature map에서 2000개의 영역을 찾아 SPP를 적용하여 고정된 크기의 feature를 얻어냄
SVM = Support Vector Machine : 데이터 분류기법
Bbox reg = Bounding box regression : 선형 회귀 모델 -> 물체를 정확히 감싸도록 조정
실험 결과
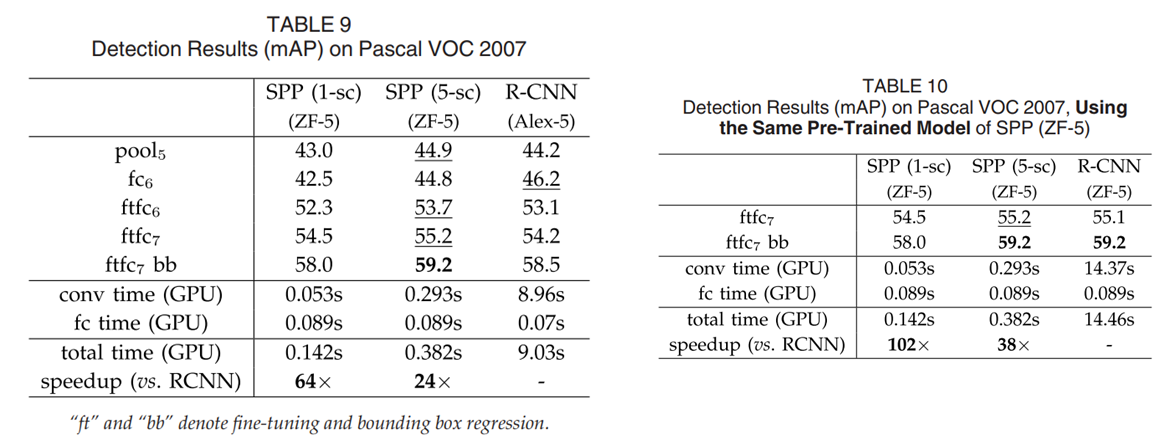
Leave a comment