
[논문리뷰] ResNet - Deep Residual Learning for Image Recognition
[논문리뷰] ResNet - Deep Residual Learning for Image Recognition
Degradation Problem
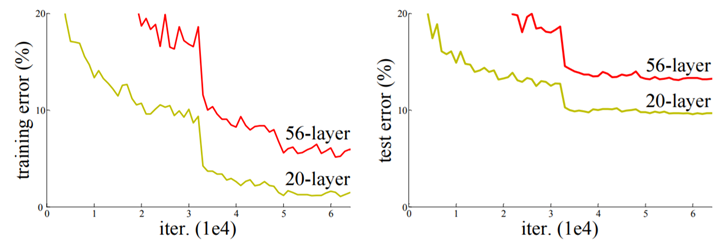
-
layer를 많이 쌓은 만큼 network의 성능이 좋아질까?
-
layer가 깊어지게 되면 오히려 error가 높아짐 (vanishing/exploding gradients)
-
-
training error와 test error에서 모두 56-layer가 높은 것으로 보아 overfitting의 문제가 아님
-
ResNet은 identity mapping을 이용한 residual learning을 통해 layer가 깊어짐에 따른 gradient vanishing 문제를 해결
Residual Learning Framework
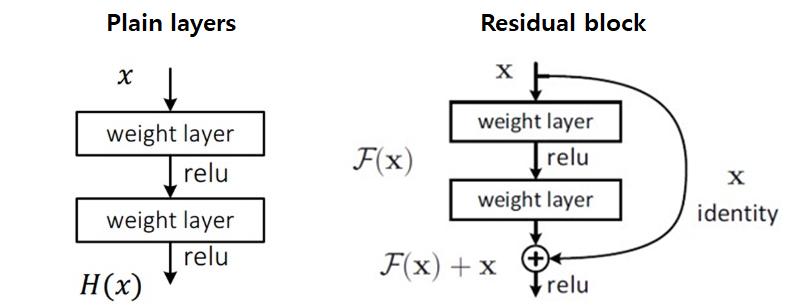
-
Plain layers
-
Input(x)을 y로 mapping 하는 H(x)를 찾음
-
H(x)-y 를 최소화 하는 방향으로 학습 수행
-
-
Residual block
-
Layer의 output F(x)를 identity(x)와 더하여 출력 결정(identity mapping)
-
F(x)+x 를 H(x)에 근사 하는 방향으로 학습 수행
-
Identity Shortcut connection
-
별도의 parameter나 computational complexity가 추가되지 않음
$y = F(x, {W_i}) + W_sx$
$F(x, {W_i})$는 학습 되어야 할 residual mapping을 나타낸다.
$W_s$는 dimension matching의 용도
-
SGD에 따른 backpropagation으로 end-to-end 학습이 가능하며, common library를 사용하여 쉽게 구현할 수 있음
-
만약 optimal function이 zero mapping보다 identity mapping에 더 가깝다면, solver가 작은 변화 F(x)를 학습하는 것이 새로운 function을 학습하는 것보다 쉬움
-
H(x) = F(x)+x 일 때, 이를 미분하면 F’(x)+1 로 모든 layer에서 gradient값이 최소 1이 되므로 vanishing gradient 문제를 해결
-
plain network와 residual network 간의 공정한 비교를 가능하게 함
(element-wise addition 연산은 무시해도 될 정도이므로 공정한 요소로 인정)
ResNet의 구조
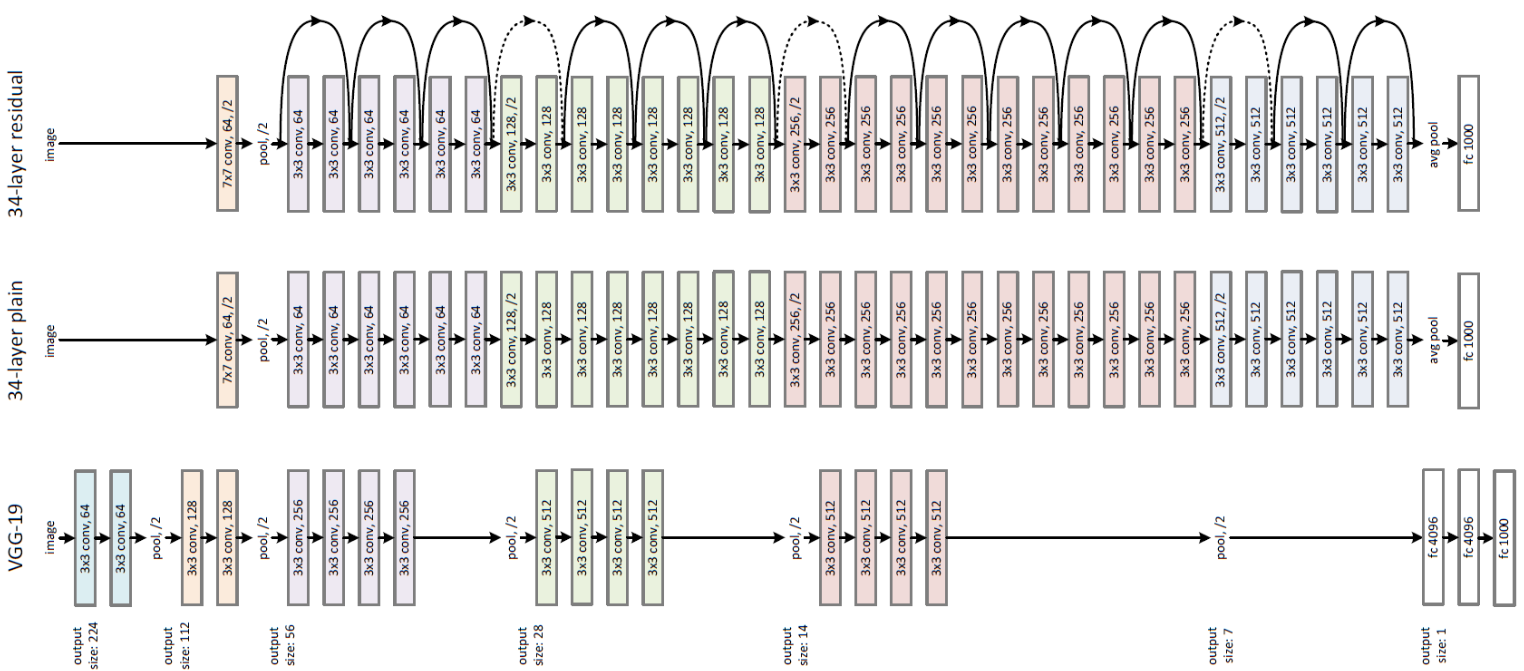
-
dotted shortcut은 dimension이 증가한 결과와 mapping하는 경우이다.
-
VGG-19 : 196억 부동소수점 연산(FLOPs)
-
34-layer plain/residual = 36억 FLOPs
-
- Plain network
-
동일한 output feature map size에 대해, layer는 동일한 수의 filter를 가짐
-
feature map size가 절반 인 경우, layer 당 time complexity를 보전하기 위해 filter의 수를 2배로 한다.
- Down sampling 시에는 strides가 2인 conv layer를 사용
-
Residual network
-
plain network를 기반으로 shortcut connection을 삽입한 residual version의 network
-
차원이 증가할 때 identity mapping을 위한 두 가지 방법
(1) zero entry를 추가로 padding하여 dimension matching
(2) 1x1 convolution을 통한 linear projection
-
Training/Validation error
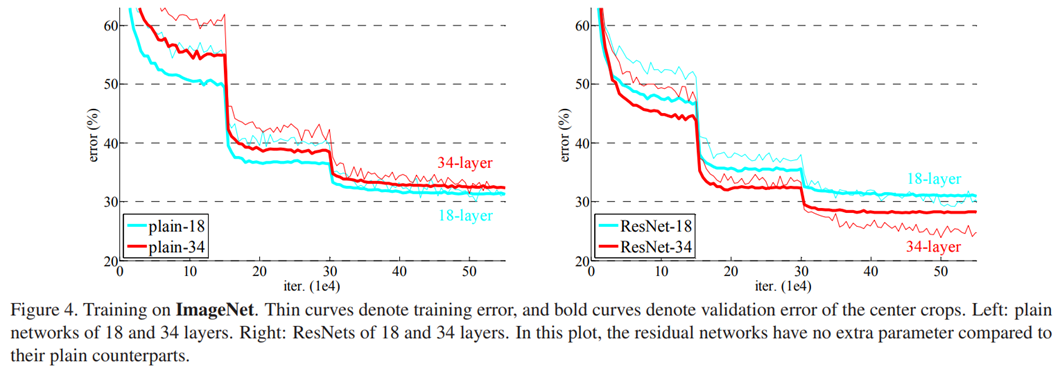
위 그래프는 ImageNet에서 training한 결과이다
-
Residual network의 error가 plain network에 비해 더 낮음
-
plain network가 Batch normalization을 포함하여 학습했기 때문에 vanishing gradient 에 의한 결과는 아님
Internal Covariance Shift
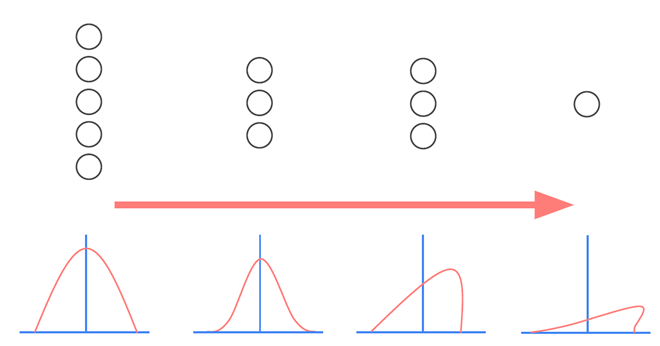
-
Network의 각 층이나 Activation 마다 input의 distribution이 달라지는 현상
-
이 현상을 막기 위해 각 layer의 input을 평균 0, 표준편차 1인 input으로 normalize 시킨다. (Batch normalization)
Batch Normalization

-
normalize된 값들에 scale factor (gamma)를 곱한 후 shift factor (beta)를 더해주고 이 변수들을 back-prop 과정에서 train 해줌
-
propagation 할 때 parameter의 scale에 영향을 받지 않는다. 따라서, learning rate를 크게 잡을 수 있음
-
Dropout을 제외할 수 있음. Dropout의 경우 효과는 좋지만 학습 속도가 다소 느려짐
Deeper bottleneck architectures
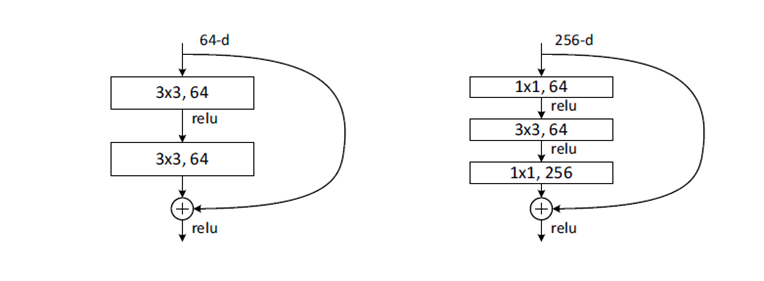
- Training time을 줄이기 위해 ResNet-50/101/152에서는 ResNet-32와 다르게 bottleneck block 을 사용함
(1×1 conv는 네트워크의 성능을 크게 저하시키지 않으면서 연결(매개 변수)의 수를 줄일 수 있다)
-
Dimension matching을 위해 projection shortcut을 사용
-
ResNet-50 과 ResNet-32의 연산량은 유사
실험 결과
1) Resnet-101/152
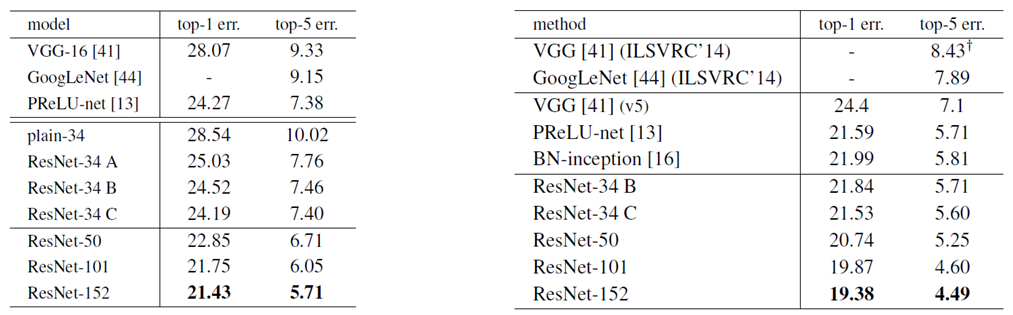
좌 : 10-crop testing error / 주 : single-model의 testing error
ResNet-34 A : zero-padding shortcut는 dimension matching에 사용되며, 모든 shortcut는 parameter-free
ResNet-34 B : projection shortcut는 dimension을 늘릴 때만 사용되며, 다른 shortcut은 모두 identity
ResNet-34 C : 모든 shortcut은 projection이다
-
Resnet-50 에 bottleneck block을 더 추가하여 구성
-
Depth가 깊어질수록 좋은 성능을 나타냄
-
기존의 method보다 좋은 성능
2) Training on CIFAR-10
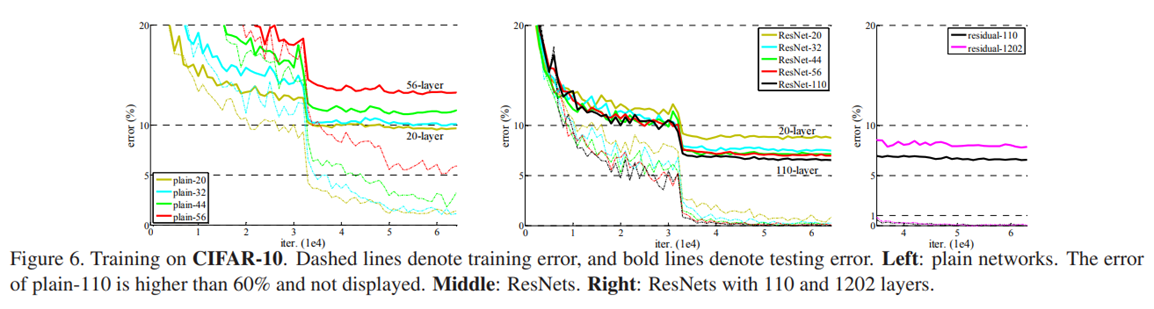
-
ResNet은 plain network와는 다르게 layer가 깊어질수록 성능 향상을 보임
-
하지만, ResNet도 layer가 너무 깊은 경우(1202) error가 증가함
-
19.4M의 parameters 존재, overfitting
Leave a comment