
[논문리뷰] Multi-scale context aggregation by dilated convolutions
[논문리뷰] Multi-scale context aggregation by dilated convolutions
Dilated Convolution
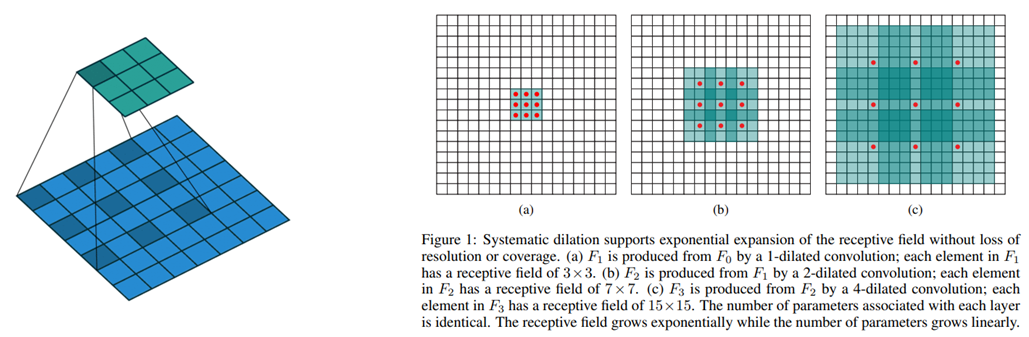
-
Convolutional layer에 필터 사이의 간격을 정의하는 dilation factor를 도입
-
Dilation factor=2인 3x3 필터는 9개의 파라미터를 사용하며 5x5 필터와 동일한 시야(view)를 가짐
-
$(F*k)(p) = \sum_{s+t=p}F(s)k(t)$
-
$(F*lk)(p) = \sum{s+lt=p}F(s)k(t)$ (l=dilation factor)
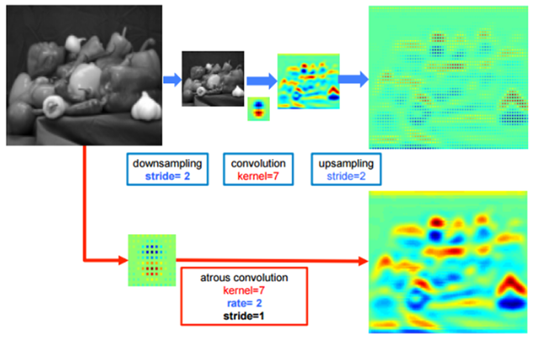
그림에서 위쪽은 down-sampling(pooling) 후 conv를 통해 large RF를 갖는 feature map을 얻고,
이를 이용해 픽셀 단위 예측을 하기 위해 다시 up-sampling을 통해 영상의 크기를 키운 결과
아래는 dilated convolution을 통해 얻은 결과
-
Receptive field의 크기가 커짐
-
Dilation factor 조정 시 다양한 scale에 대한 대응이 가능해짐
-
기존의 CNN에서는 receptive field의 확장을 위해 pooling layer를 통해 feature map의 크기를 줄인 후 convolution 연산을 수행하는 방식으로 계산
Front-end module
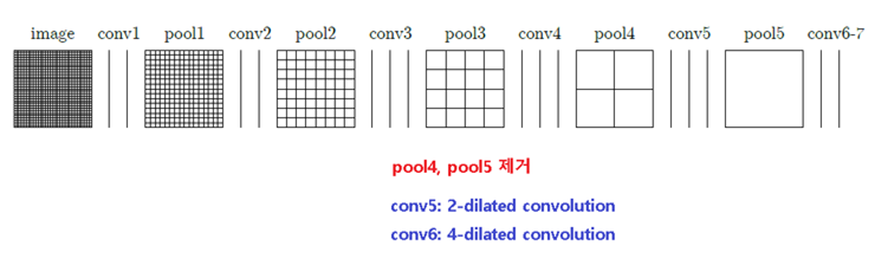
-
VGG-16 network을 수정
-
Pool 4, 5를 제거함으로써 원 영상의 1/8까지 작아져 detail을 가짐
-
Conv 5, 6은 dilated convolution을 사용함
-
기존의 구조보다 연산량이 줄어듬
Multi-Scale Context Aggregation by dilated convolutions에서는 크게 두 가지의 network module로 구성됨 (Frond-end module과 context module)
뒷단이 크게 도움이 되지 않기에 제외함
FCN은 이를 그대로 두었기에 feature map의 크기가 1/32까지 작아지고 이로 인해 좀 더 해상도가 높은 pool4, 3의 결과를 사용하기 위해 skip layer라는 것을 포함시킴
실험결과

Multi-Scale Context Aggregation (The Context Module)
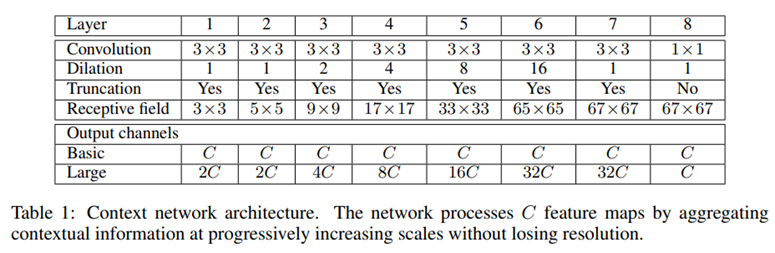
-
다중 scale의 context를 잘 추출해내기 위한 context module
-
C개의 feature map을 input값으로 받고, output을 C개의 feature map으로 생성함
-
$k^b (t,a) = 1{t=0} 1{a=b}$ (a = index of feature map , b = index of output map)
이 모듈은 어느 dense prediction architecture에 사용을 해도 괜찮음 (C->C)
Basic type은 feature map의 개수가 동일하지만 large type은 feature map의 개수가 늘었다 최종단만 feature map의 개수가 원래의 개수와 같아지도록 구성됨.
초기화는 RNN에서 자주 쓰이는 방법
실험 결과

Leave a comment