
[논문리뷰] DBPN - Deep Back-Projection Networks for Single Image Super-resolution
[논문리뷰] DBPN - Deep Back-Projection Networks for Single Image Super-resolution
DBPN의 구조
Down projection의 결과는 concat하여 Up projection의 input으로 들어가고, 채널수가 다를땐 1x1 conv를 이용하여 맞춰준다.
-
Initial Feature Extraction
-
Back-Projection Stages
-
Reconstruction
으로 구성됨
Initial Feature Extraction
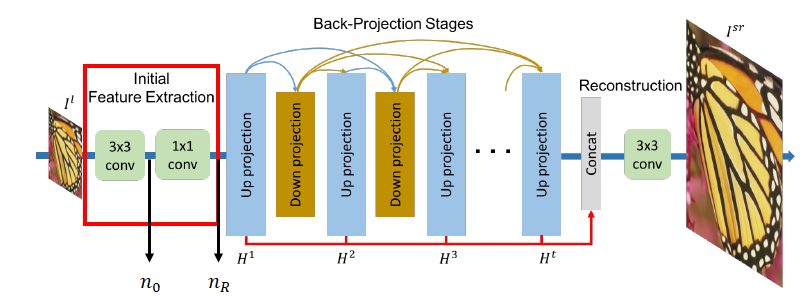
- 3x3 컨볼루션 레이어를 통하여 n_0채널의 initial LR feature maps을 얻음
- $L^0∈R^{M^l×N^l×n_0}$
- 1x1 컨볼루션을 통하여 projection 전 $n_R$채널로 차원을 줄임 ($n_0>n_R$)
Back-Projection Stages
1) training set의 크기에 따른 결과
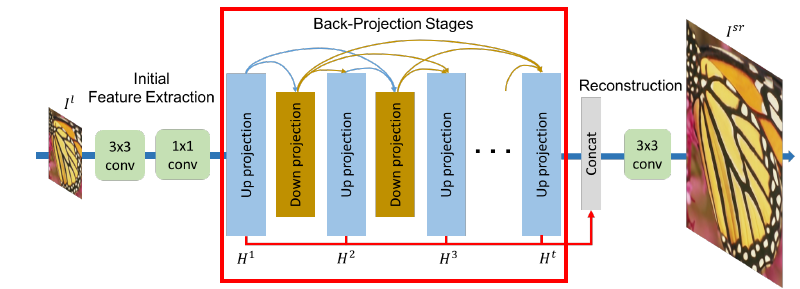
- Up, down projection을 통해 LR, HR feature maps을 얻음
- $L^t∈R^{M^l×N^l×n_R}, H^t∈R^{M^h×N^h×n_R}$
- Dense connection을 통하여 성능 증가
Reconstruction
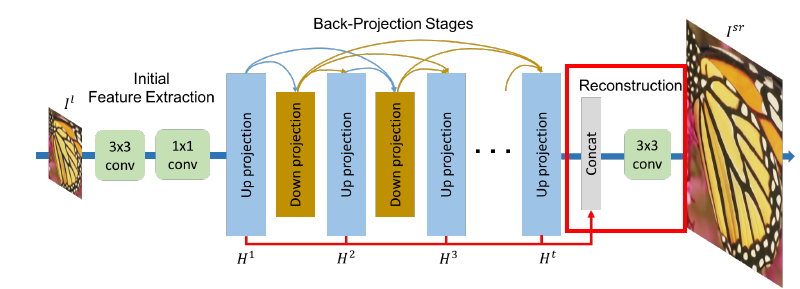
- Up projection의 output을 concatenate 해줌 (deep concatenation)
- Convolution layer를 통해 HR 이미지 복원
- $I^{sr}=f_{Rec} ([H^1, H^2,…,H^t])$
$f_Rec$ : 3x3 conv를 통한 Reconstruction
[…] : concat의 결과
각각의 projection unit이 HR의 다른 detail들을 보임 -> 이를 합하여 결과의 detail을 높임
Recurrent DBPN
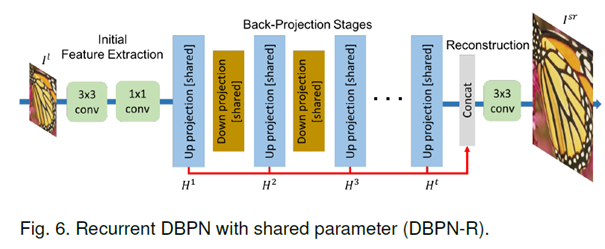
- 하나의 up, down projection unit 사용
- Dense connection 없이 파라미터들이 공유됨
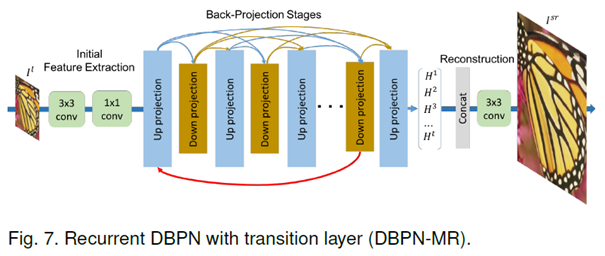
- 마지막 up, down projection unit이 transition layer로 쓰임
- N번째 반복의 output = H^n
- 마지막 up projection unit은 이전의 모든 output을 얻음
실험 결과
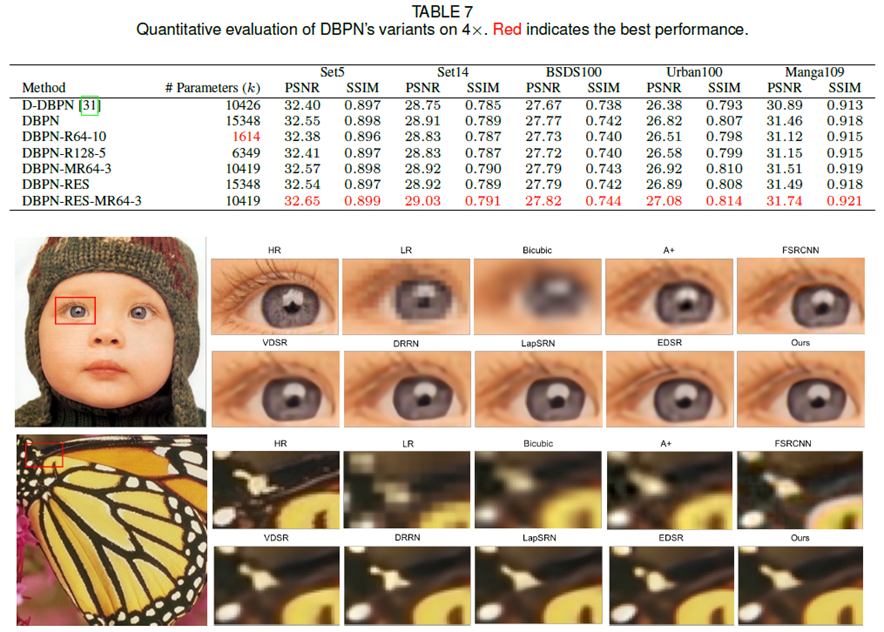
DBPN-R64-10 : $n_R$=64, t=10 으로 640개의 HR feature 생성
Leave a comment