
[논문리뷰] SRCNN - Image Super-Resolution Using Deep Convolutional Networks
[논문리뷰] SRCNN - Image Super-Resolution Using Deep Convolutional Networks
Super Resolution (SR) 이란?
Super Resolution이란, 저해상 이미지(low-resolution image)를 고해상 이미지(high-resolution image)로 복원하는 과정을 의미한다.
이전까지 주로 쓰이던 방식은 Sparse-coding based method (SC)이라고 논문에서 언급하고 있다.

본 논문은 딥러닝을 사용한 최초의 SR 기법이며, 간단한 CNN 구조로 기존의 기법에 비해 훌륭한 성능을 보여주어 이후 딥러닝을 이용한 SR의 발전에 불을 지폈다.
SRCNN의 구조
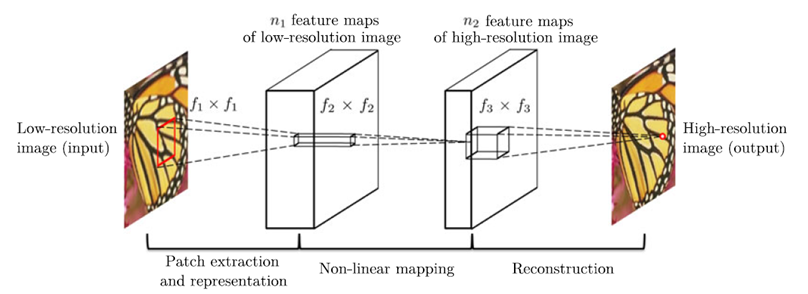
SRCNN의 구조(network structure)는 위와 같다.
-
저해상도 이미지를 Bicubic interpolation을 이용하여 upscale한 후, 그 이미지를 CNN을 사용한 SR 알고리즘을 통해 원본과 유사한 고해상도 이미지로 변화 시키는 것이 목표이다.
-
Bicubic interpolation이란, 인접한 16화소의 거리에 따른 가중치의 곱을 사용해 결정하는 기본적인 SR 알고리즘이다.
그림과 같이 3개의 layer들로 구성되어있으며, 각각의 layer에 대한 설명은 아래와 같다.
1) Patch extraction and representation
저해상도 이미지에서 feature map을 추출한다.
$F_1(Y) = max(0,W_1*Y+B_1)$
2) Non-linear mapping
추출한 feature map에 비선형성을 추가한다.
$F_2(Y) = max(0,W_2*F_1(Y)+B_2)$
3) Reconstruction
feature map을 이용해 고해상도 이미지를 추출한다.
$F(Y) = W_3*F_2(Y)+B_3$
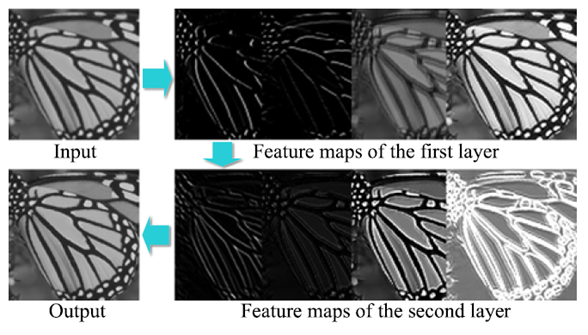
각각의 layer들을 통과한 후 나온 feature map을 1채널 이미지로 나타낸 영상은 위와 같다.
논문에서는 이를 first layer에서는 서로 다른 방향에서의 윤곽선을, second layer에서는 윤곽선의 세기를 나타낸다고 언급하고 있다.
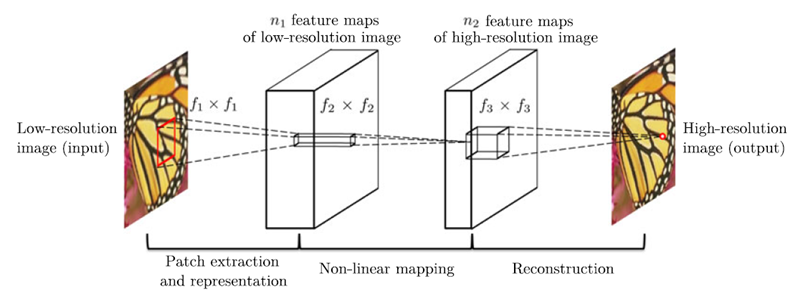
위의 구조를 다른방식으로 나타낸 사진이며,
$n_1$ = 64, $n_2$ = 32, $f_1$ = 9, $f_2$ = 1, $f_3$ = 5 를 기준으로 하여
필터의 개수(n)과 필터의 크기(f) 등을 변경해가며 실험을 진행했다.
실험 결과
1) training set의 크기에 따른 결과
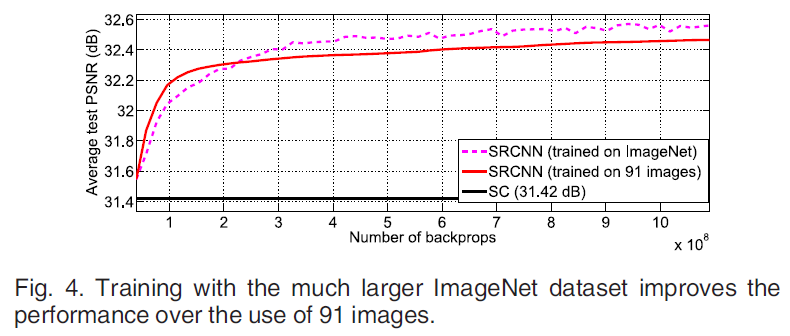
-
SRCNN은 larger training set 을 사용할수록 효과적이다.
-
이후의 모든 실험에서 SRCNN은 ImageNet으로 train을 진행했다.
-
저자들은 SRCNN은 91개의 이미지도 train하기에 충분하여 PSNR의 차이가 크지 않다고 설명하고 있다.
2) 필터의 개수에 따른 결과
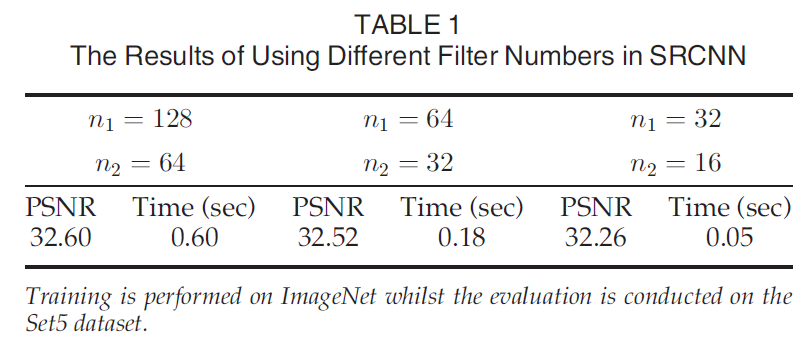
필터의 개수가 많아짐에 따라 성능향상은 크게 없지만 시간은 크게 증가하였다.
(Upscaling Factor = 3)
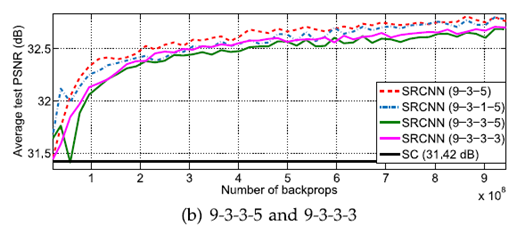
3) 2번째 layer의 필터의 크기에 따른 결과
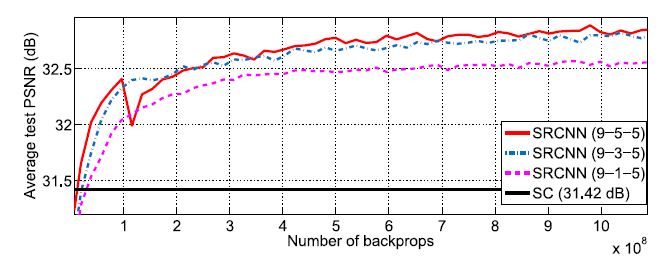
2nd layer에서의 필터의 크기가 클수록 성능이 좋아진다.
하지만, 9-1-5, 9-3-5, 9-5-5 의 parameter의 수는 각각 8,032, 24,416, 57,184로 증가하여 수행속도가 현저히 감소했다.
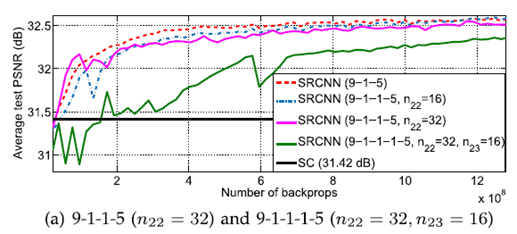
4) layer의 개수에 따른 결과
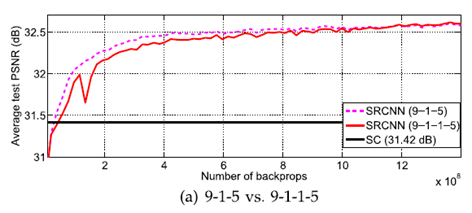
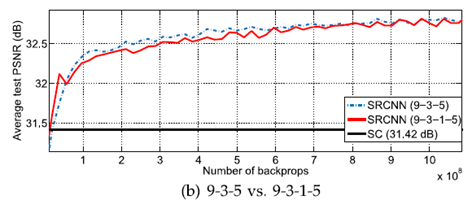
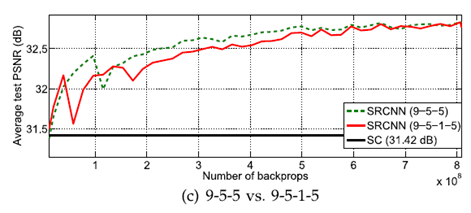
$n_{22}$ = 16, $f_{22}$ = 1인 convolution layer를 2nd layer 뒤에 추가했지만
눈에 띄는 성능차이를 보여주지는 못했다.
5) 종합
-
Layer를 추가하거나 filter size를 늘려도 성능은 개선되지 않았음을 알 수 있다.
-
그 이유로 layer가 깊어지면 적당한 learning rate를 찾기 어렵고, cost를 수렴하게 하는 learning rate를 찾아도 local minimum일 수 있다.
기존의 SR 기법들과의 비교
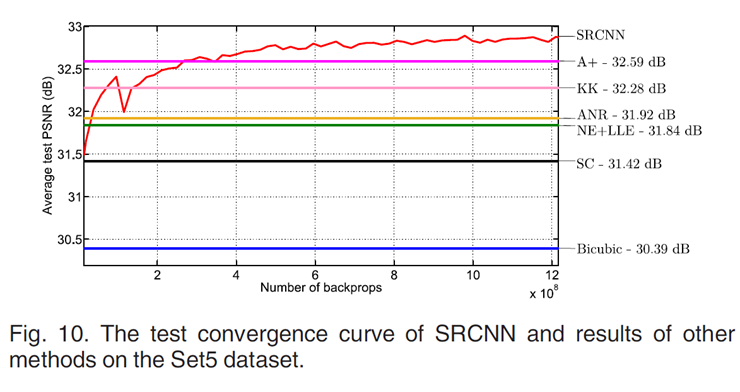
Fig. 10. 은 Set5 dataset으로 SRCNN과 기존의 SR method들을 test한 결과이다.

Fig. 12. 는 수행속도와 함께 나타낸 그래프이며 SRCNN 의 filter size에 따라 Running time와 PSNR값의 차이가 있음을 알 수 있다.
-
MATLAB/C++ 구현에서도 Running time 의 차이는 크지 않다.
-
이전 층의 출력이 다음 층의 입력으로 들어가는 구조(feed-forward) 이기 때문에 다른 기법들에 비해 Running time이 빠르다.
학습 전략
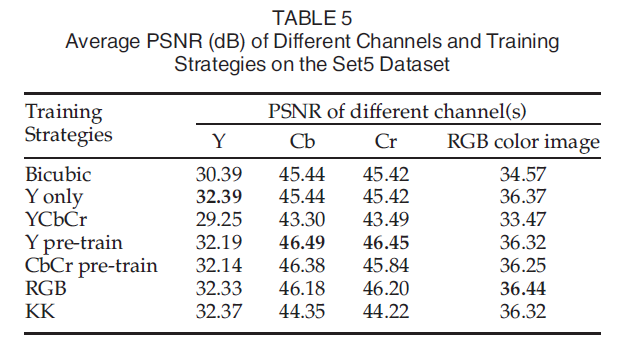
위 표는 서로 다른 채널에 대해 여러 SR 기법들을 적용한 결과이다.
-
Y only : Y 채널만 학습하고 Cb, Cr 채널은 Bicubic interpolation 을 적용한 학습 전략.
-
위 방식은 3종류의 채널을 모두 학습시키는 것 보다 속도가 빠르지만, RGB 채널을 학습시키면 더 좋은 결과를 얻을 수 있다.
Leave a comment