
[논문리뷰] VDSR - Accurate Image Super-Resolution Using Very Deep Convolutional Networks
[논문리뷰] VDSR - Accurate Image Super-Resolution Using Very Deep Convolutional Networks
SRCNN의 한계
-
SRCNN은 layer가 얕아 좁은 이미지영역에 대한 정보(contextual information) 만 사용한다. (Receptive Field = 13x13)
-
또한, training시 loss의 수렴속도가 느리고, 단일 scale에 대해서만 사용가능 하다는 단점이 있다. 새로운 scale이 요구될 때 그 scale에 맞게 새로 학습을 해야한다.
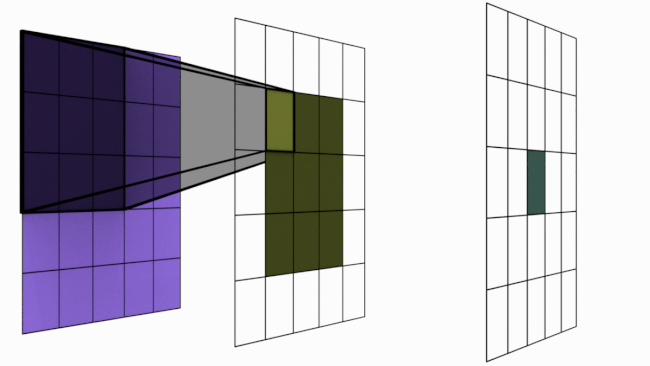
Receptive field
-
Receptive field란, 하나의 픽셀을 복원하기 위해 이용되는 주변의 정보영역을 의미한다.
-
특정 위치에 있는 픽셀들은 그 주변에 있는 일부 픽셀들 하고만 correlation이 높고 거리가 멀어질수록 그 영향은 감소한다.
-
따라서, 전체 영역에 대해 서로 동일한 중요도를 부여하여 처리하는 대신 범위(Receptive field)를 한정해 처리를 하면 훨씬 효율적이다.
-
VDSR에서는 receptive field가 41x41로 SRCNN의 13x13보다 큰 영역을 가진다.
VDSR의 장점
1) Layer가 깊어 넓은 Receptive field를 가지는 덕에 넓은 영역의 contextual information 을 사용할 수 있다.
-
20layer에서 3x3 filter 사용시 receptive field는 41x41
-
contextual information : 주변 정보와의 관계 (맥락정보)
2) Residual Learning과 높은 Learning rate를 사용하여 Convergence가 빠르다. Learning rate가 커지면 cost가 발산할 수 있는데, 이를 방지하기 위해 Adjustable gradient clipping 을 사용했다.
- gradient clipping에 대해서는 밑에서 자세히 언급.
3) 하나의 network으로 여러 scale factor 값 들에 대해 SR을 효율적으로 수행할 수 있다.
4) Zero-padding를 사용하여 input과 output의 크기가 같고, 이미지 외곽의 정보도 정확하게 복원
-
SRCNN은 padding을 사용하지 않아 convolution시 size가 작아짐에 따라서 외곽의 정보를 잘랐지만, VDSR은 padding을 통해 convolution시에도 size가 일정하고, 외곽의 정보도 정확하게 복원함
-
SRCNN은 layer를 통과해서 나온 feature map의 크기가 각기 달라서, 효과적인 학습 수렴을 위해서는 layer마다 learning rate가 다 달라야 했다.
-
VDSR은 zero-padding을 통해서 feature map의 크기가 항상 같기 때문에, 모든 layer가 하나의 learning rate를 사용해도 충분하며, 이로 인해 학습시켜야 할 parameter 수가 줄어들어 학습 속도가 빨라졌다.
Gradient clipping
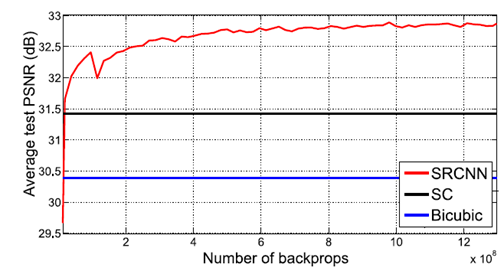
위 그래프는 SRCNN에서 network이 깊어짐에 따라 성능의 변화를 나타내는 그래프이다.
-
위 그래프에서 볼 수 있듯이 SRCNN에서는 network가 깊어질 때 성능저하를 나타낸다.
-
그 이유로 learning rate가 작아 수렴에 오래 걸리고, 수렴전에 training을 종료했기 때문이라고 VDSR의 저자들은 언급하고 있다.
-
VDSR에서는 20층의 layer를 쌓고, Learning Rate를 크게 하여 빠르게 수렴하게 했다.
-
Learning rate 가 커지면 exploding gradient 가 나타날 수 있지만, gradient를 [-Θ, Θ]의 범위로 고정시켜 이를 방지할 수 있다. (Gradient clipping)
-
VDSR에서는 Learning Rate를 γ라 할 때, gradient의 범위를 [-Θ/ γ , Θ/ γ] 로 고정했고, 이를 Adjustable Gradient Clipping이라 한다.
(SRCNN에서 며칠이 걸린걸 4시간만에 해결했다고 함)
Residual learning
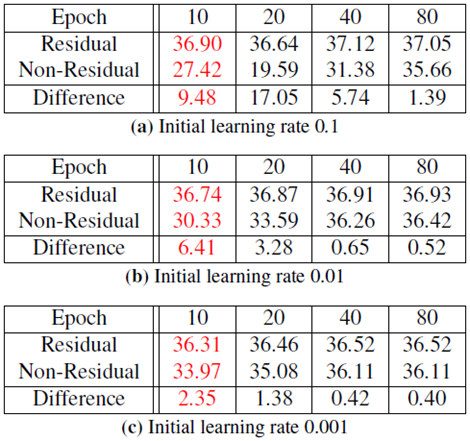
위 표는 Residual 을 사용했을 때와 사용하지 않았을 때의 성능을 보여준다.
- SR에서는 input, output간의 차이가 크지 않으므로, Low-Resolution image에 High-Resolution image 가 가지는 디테일(Residual) 만 부여하는 방식으로 학습을 진행한다.
(Residual 사용시 고해상도의 이미지가 가지는 디테일에 대해서만 배우면 되므로 성능이 빠르고 정확하게 수렴)
- SRCNN에서는 input image를 가지고 완전히 새로운 output image를 만들어 내므로 속도와 정확도가 낮다.
VDSR의 구조
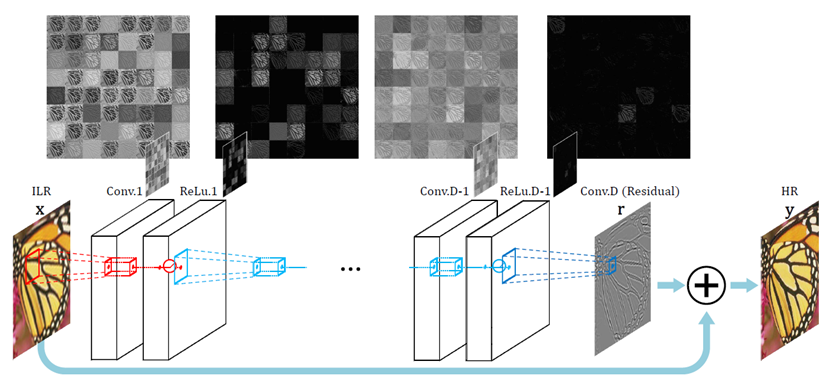
-
20 개의 layer로 구성되있고, layer당 64개의 3x3필터를 사용한다.
-
64개 (그림에선 D개)의 layer를 지나 만들어진 residual 값과 input을 더하여 output인 HR이 나오게 된다. (Residual Learning)
Vanishing/Exploding Gradient
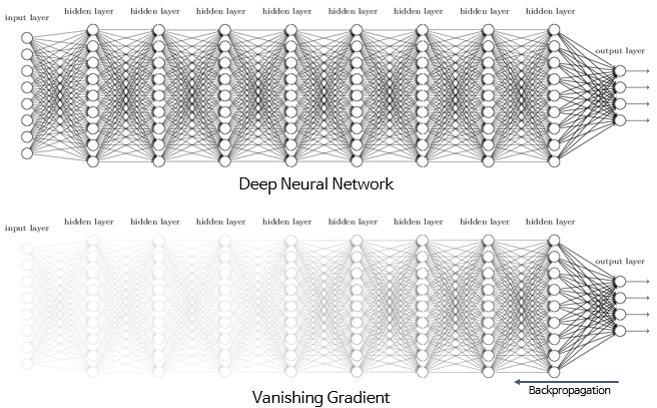
-
depth가 깊은 network에서는 backpropagation시 gradient가 점점 작아져 가중치 매개변수가 업데이트 되지 않을 수 있다. (Vanishing gradient)
-
Gradient를 backpropagation을 통해 뒷 단으로 전파하며 weight를 update해 주는데, gradient가 작은 경우 작은 gradient값이 곱해져 input과 가까운 layer의 gradient값들은 output에 거의 반영이 되지 않는다.
-
이와 반대로 gradient가 점점 커지는 경우가 있는데, 이를 exploding gradient라 한다.
-
Learning rate가 클 경우 역시 exploding gradient가 일어나기도 하는데, VDSR에서는 앞서 언급한 gradient clipping을 통해 이를 방지했다.
실험 결과
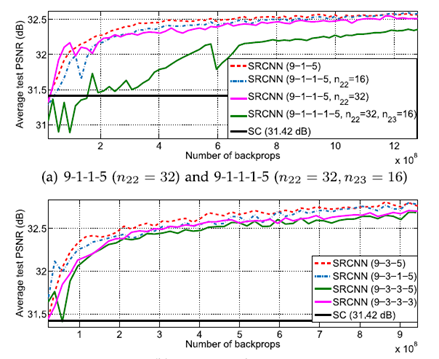
1) Depth vs Performance
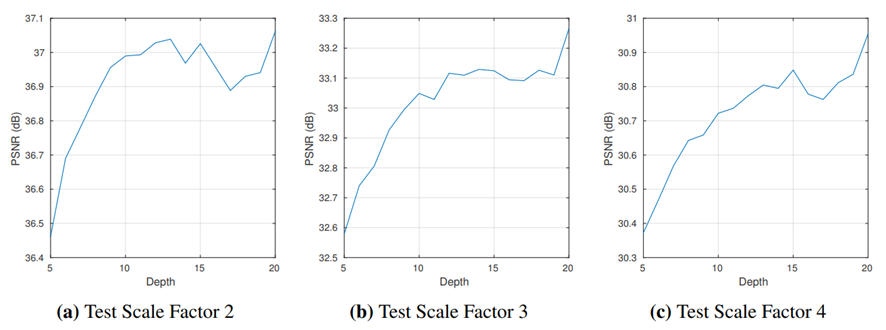
-
여러 Scale Factor에 대해 실험을 해봤을 때, depth가 깊을 수록 높은 PSNR값을 가진다.
-
Depth가 깊어질수록 receptive field도 커지기 때문.
-
넓은 Receptive field는 네트워크가 이미지를 예측하기 위해 더 많은 context를 이용한다는 의미를 가진다.
-
하지만, depth가 커질수록 속도는 줄어든다.
2) Learning rate를 변경해가며 실험
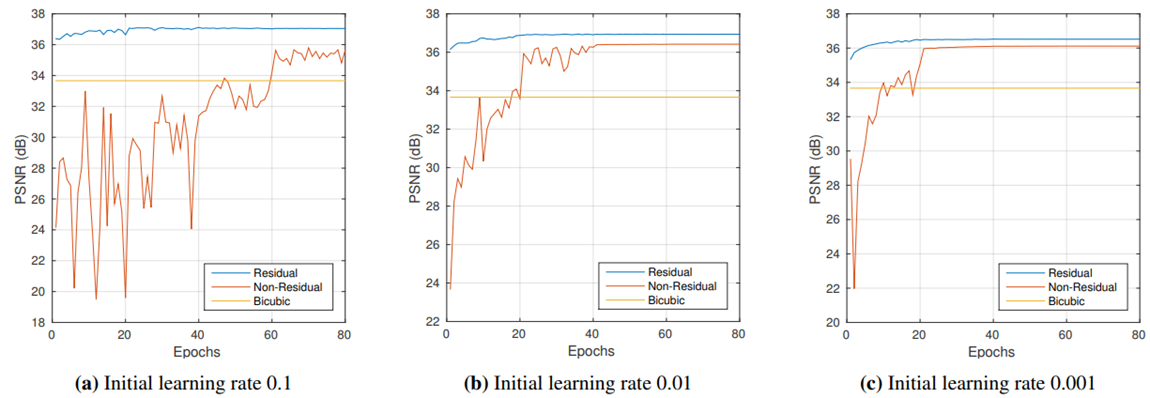
-
Residual Learning은 높은 initial learning rate를 적용시켜도 빠른 Convergence가 가능하게 한다.
-
작은 learning rate로는 큰 learning rate 사용시 나왔던 성능에 도달할 수 없다.
-
lr = 0.1 일 때에는 36.9까지 PSNR이 나왔지만, lr = 0.001 일 때에는 PSNR이 36.52에서 더 이상 증가하지 않았다.
-
lr = 0.001일때 PSNR이 더 이상 증가하지 않은 이유는 local minimum에 빠졌기 때문이다.
Single model for Multiple Scales

-
single-scale data에 대해서만 학습된 네트워크는 다른 scale 문제에 적용할 수 없음
-
Multiple scale로 학습한 모델의 경우 각 scale의 PSNR이 각 scale에 대한 single-scale로 학습한 경우와 유사한 PSNR 값을 가짐
-
Multiple scale로 학습한 모델은 큰 scale에서 뛰어난 성능을 보임
결과 영상

Leave a comment